Obliczenia przyspieszone umożliwiają ogromne skoki w wydajności i efektywności energetycznej w porównaniu do tradycyjnych obliczeń CPU. Wprowadzenie tych innowacji wymaga pełnozakresowego podejścia na poziomie centrów danych, obejmującego chipy, systemy, sieci, oprogramowanie i algorytmy. Wybór odpowiedniej architektury do odpowiedniego obciążenia z najlepszą efektywnością energetyczną jest kluczowy dla maksymalizacji wydajności i minimalizacji śladu węglowego centrum danych.
Chociaż obciążenia są coraz częściej przyspieszane przez GPU, wiele zastosowań wciąż działa głównie na tradycyjnych CPU—szczególnie kod, który jest rzadki i zawiera „rozgałęzione” zadania serializowane, takie jak analityka grafów. Równocześnie centra danych stają się coraz bardziej ograniczone pod względem mocy, co ogranicza rozwój ich możliwości. Oznacza to, że wszystkie obciążenia, które mogą być przyspieszone, powinny działać w trybie przyspieszonym. Te, które nie zostały przyspieszone, powinny działać na najbardziej efektywnych obliczeniach CPU, jakie są możliwe.
Procesor NVIDIA Grace łączy 72 rdzenie Arm Neoverse V2 o wysokiej wydajności i efektywności energetycznej, połączone z architekturą NVIDIA Scalable Coherency Fabric (SCF), która dostarcza 3,2 TB/s przepustowości bisection—dwa razy więcej niż tradycyjne CPU. Ta architektura umożliwia płynny przepływ danych między rdzeniami CPU, pamięcią podręczną, pamięcią i I/O systemowym, maksymalizując wydajność systemu. Grace jest pierwszym procesorem CPU dla centrum danych, który wykorzystuje pamięć LPDDR5X wysokiej prędkości klasy serwerowej z szerokim podsystemem pamięci, który zapewnia 500 GB/s przepustowości przy jednej piątej mocy tradycyjnej pamięci DDR przy podobnych kosztach.

Ilustracja 1. Superchip NVIDIA Grace (po lewej) i superchip Grace Hopper (po prawej)
Procesor NVIDIA Grace napędza wiele produktów NVIDIA. Może współpracować z procesorami graficznymi NVIDIA Hopper lub NVIDIA Blackwell, tworząc nowy typ procesora, który ściśle łączy CPU i GPU, aby przyspieszyć generatywną AI, obliczenia o wysokiej wydajności (HPC) oraz obliczenia przyspieszone. Ponadto portfolio procesorów NVIDIA Grace obejmuje zarówno superchip CPU NVIDIA Grace, który stanowi serce serwera z podwójnym gniazdem, jak i Grace CPU C1, który oferuje niesamowitą wydajność w konfiguracji z jednym gniazdem.
Superchip NVIDIA GH200 Grace Hopper łączy przełomową wydajność procesora graficznego NVIDIA Hopper z wszechstronnością procesora NVIDIA Grace w jednym superchipie, połączonym z interfejsem wysokoprzepustowym, koherentnym pamięciowo NVIDIA NVLink Chip-2-Chip (C2C) o przepustowości 900 GB/s, co zapewnia 7-krotną przepustowość w porównaniu do PCIe Gen 5. Koherencja pamięci NVLink-C2C zwiększa produktywność deweloperów, wydajność oraz ilość pamięci dostępnej dla GPU. Wątki CPU i GPU mogą równocześnie i przezroczysto uzyskiwać dostęp do pamięci zarówno CPU, jak i GPU, co pozwala skoncentrować się na algorytmach zamiast zarządzania pamięcią.
W ciągu ostatnich dwóch dekad inżynieria wspomagana komputerowo (CAE) zrewolucjonizowała proces rozwoju produktów. Możliwość szybkiej oceny wydajności fizycznej projektu w wirtualnym środowisku, bez konieczności tworzenia fizycznego prototypu, zaoszczędziła czas i pieniądze. Przyjęcie CAE było kluczowe dla wielu sektorów, w tym przemysłu motoryzacyjnego, gdzie pomogło im odnieść sukces na konkurencyjnym rynku i umożliwiło szybkie dostosowanie się do trendów branżowych, takich jak elektryfikacja.
Dynamika płynów obliczeniowych (CFD) oraz obciążenia związane z analizą zderzeń to symulacje, które wymagają maksymalnej wydajności sieciowej, ultra-niskiej latencji oraz natywnych zrzutów CPU, takich jak RDMA, aby osiągnąć optymalną wydajność serwera i produktywność aplikacji dla skalowalności multinode. NVIDIA Quantum InfiniBand spełnia te wymagania, oferując ultraniskie prędkości danych, minimalną latencję, inteligentne przyspieszenia i doskonałą efektywność, umożliwiając wyjątkową skalowalność i wydajność.
Ansys jest wiodącym dostawcą narzędzi CAE. Ten post bada wydajność Ansys LS-DYNA, która jest powszechnie używana do analizy zderzeń, oraz oprogramowania Ansys Fluent, które jest powszechnie używane do analizy aerodynamiki CFD. Symulacja Ansys LS-DYNA jest przede wszystkim obciążeniem CPU, więc będzie testowana na procesorze NVIDIA Grace. Oprogramowanie Ansys Fluent korzysta z natywnego rozwiązania CUDA, więc będzie uruchamiane na procesorze NVIDIA Grace Hopper. Obciążenia te są kluczowe w przemyśle motoryzacyjnym. Analiza zderzeń często zajmuje ponad 50% obciążenia HPC w motoryzacji, podczas gdy CFD jest największym z pozostałych obciążeń.
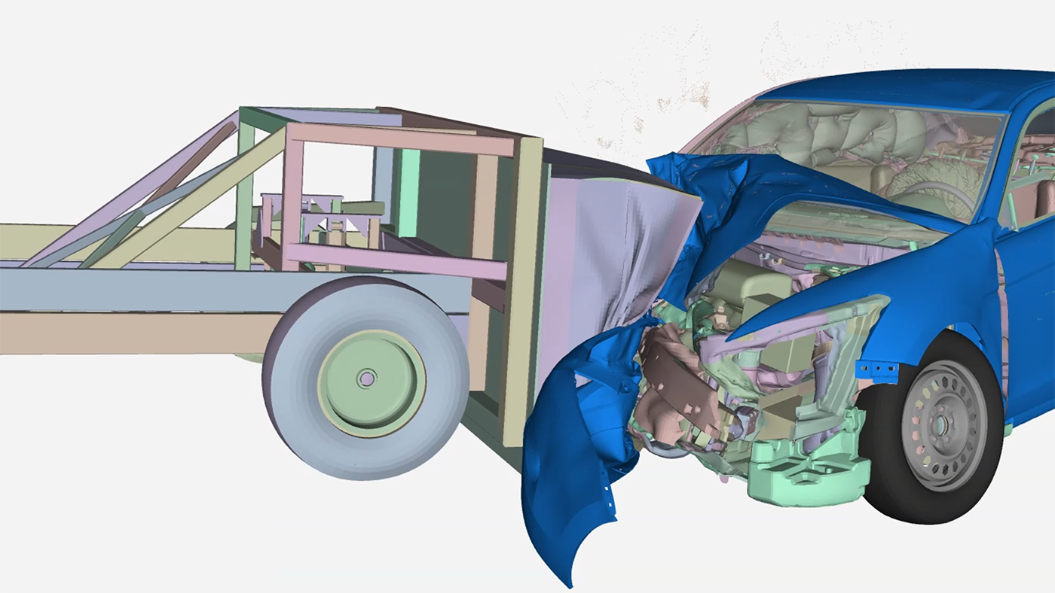
Rysunek 2. Model symulacji zderzeń benchmarku Odm dla oprogramowania Ansys LS-DYNA
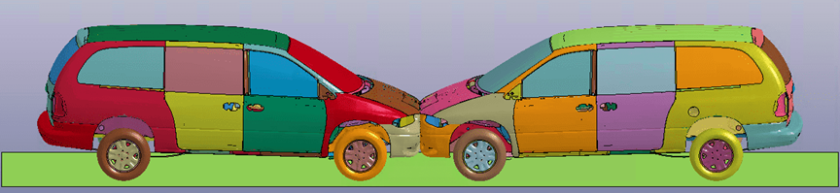
Rysunek 3. Modele symulacji zderzeń benchmarku ar2car dla oprogramowania Ansys LS-DYN
Kluczowym elementem przy wdrażaniu jakiejkolwiek nowej platformy sprzętowej jest posiadanie ekosystemu oprogramowania. Ponieważ Grace opiera się na architekturze Arm, istnieje bogaty i rozwijający się ekosystem wsparcia. Obejmuje to wiele narzędzi oferowanych przez Ansys, takich jak oprogramowanie LS-DYNA.
Wydajność Ansys LS-DYNA na procesorze NVIDIA Grace
Rysunek 4 pokazuje wydajność procesora NVIDIA Grace w porównaniu do innych obecnie dostępnych opcji x86 dla modeli car2car_20m i odm_10m. Pomiar wydajności jest oparty na czasie CPU potrzebnym do zakończenia analizy.
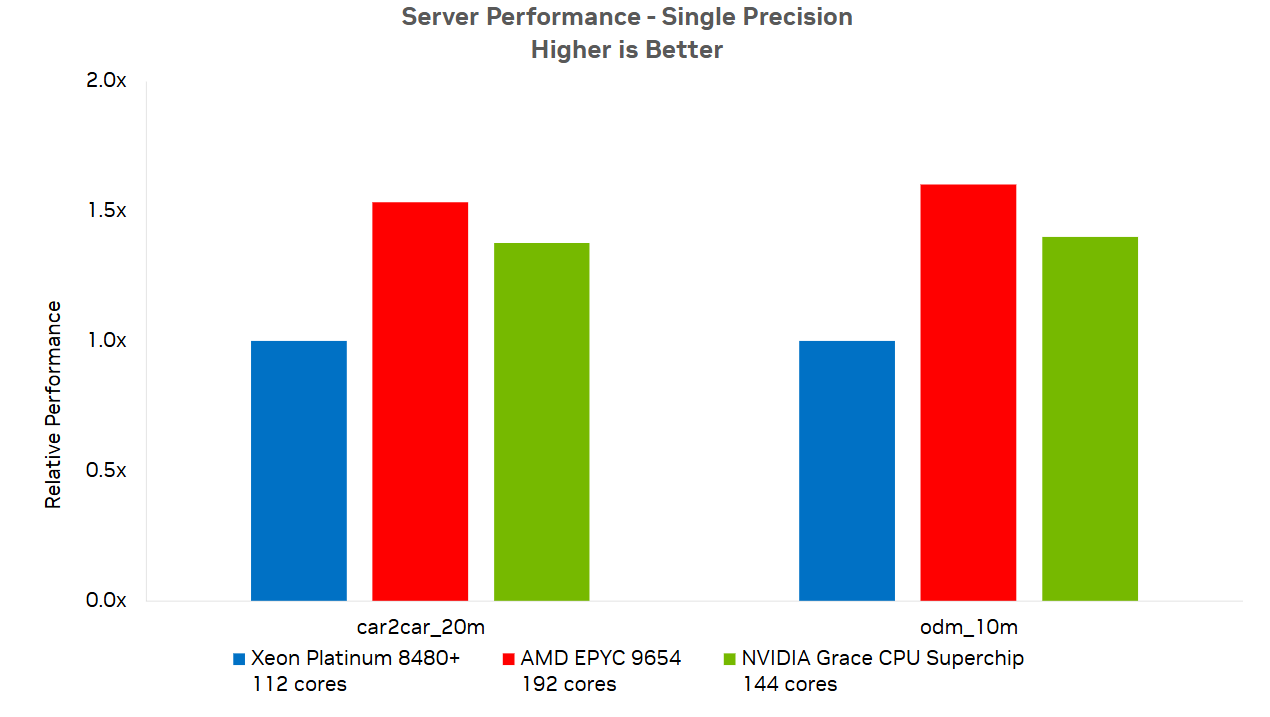
Rysunek 4. Wydajność procesora NVIDIA Grace w porównaniu do wielu standardowych opcji x86
Rysunek 5 pokazuje przewagę superchipa NVIDIA Grace w zakresie efektywności energetycznej. Grace może obsługiwać zarówno przypadki car2car_20m, jak i odm_10m przy znacznie mniejszym zużyciu energii, co prowadzi do obniżenia kosztów i bardziej zrównoważonych obliczeń. Wiele centrów danych jest ograniczonych pod względem mocy, więc zmniejszone zużycie energii pozwala na uzyskanie większej wydajności w ramach tego samego budżetu energetycznego.
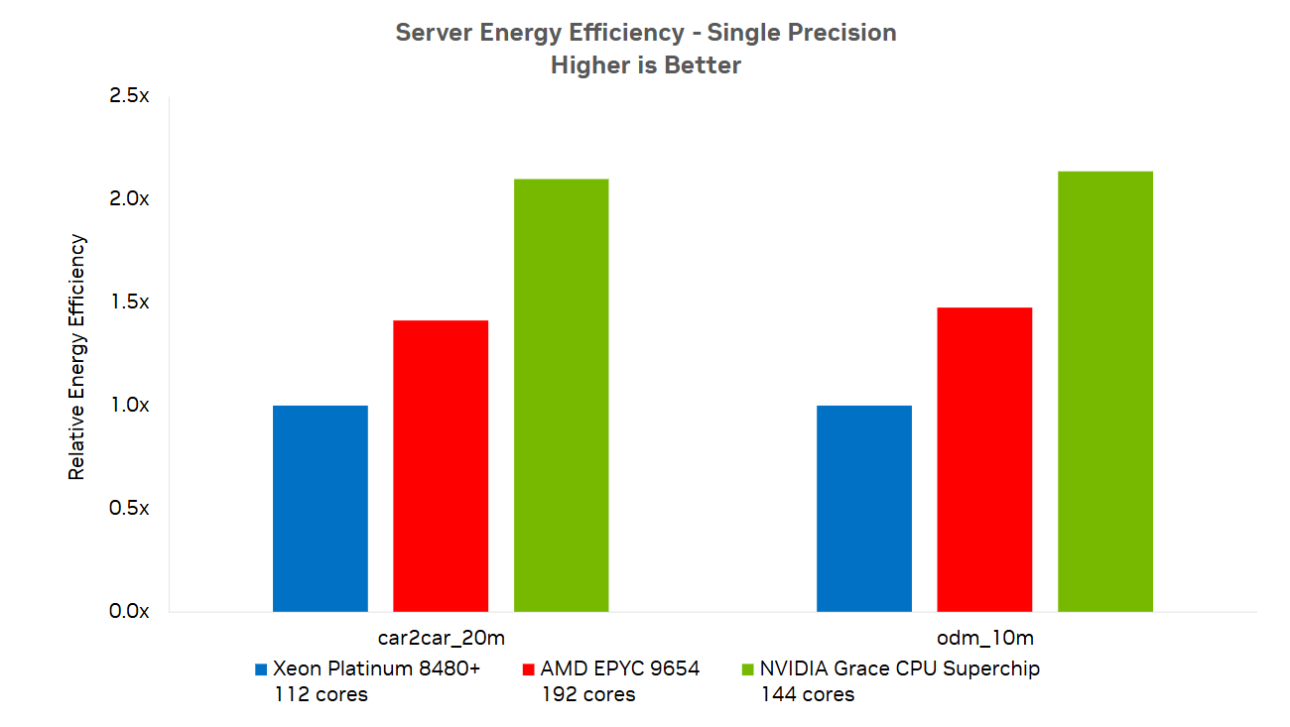
Rysunek 5. Procesor NVIDIA Grace oferuje lepszą efektywność energetyczną w porównaniu do różnych architektur x86
Ponieważ symulacje LS-DYNA często są uruchamiane na kilku węzłach, aby skrócić czas realizacji i szybciej uzyskać informacje analizy inżynieryjnej, porównaliśmy skalowanie 1-8 węzłów procesora Grace w porównaniu do 1-8 węzłów Intel Sapphire Rapids.
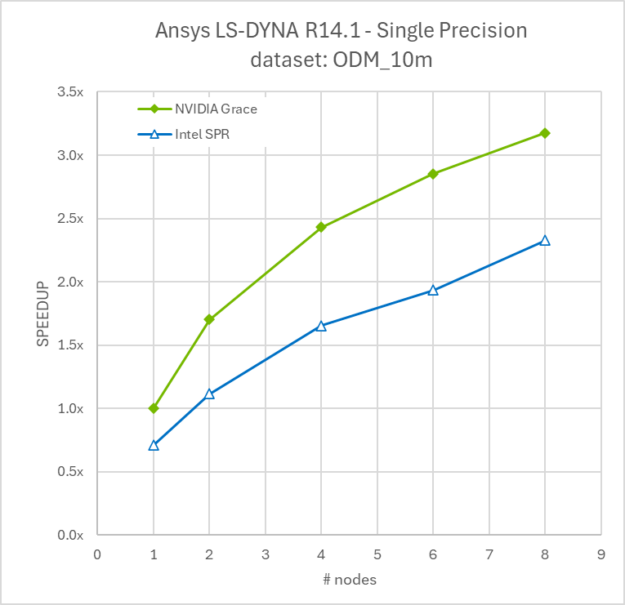
Rysunek 6. Skalowanie multinode modelu ODM_10m od 1 do 8 węzłów dla superchipa procesora NVIDIA Grace oraz Intel Xeon Platinum 8480+
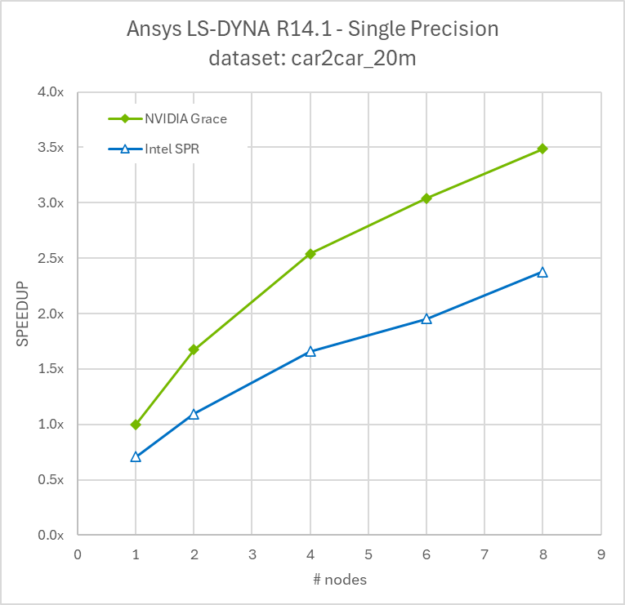
Rysunek 7. Skalowanie multinode modelu car2car_20m od 1 do 8 węzłów dla superchipa procesora NVIDIA Grace oraz Intel Xeon Platinum 8480+
NVIDIA Grace Superchip 480 GB LPDDR5X, AMD EPYC 9654 768 GB DDR5 oraz Intel Xeon Platinum 8480+ z 1 TB DDR5. System operacyjny: CentOS 7.9 (Grace) Ubuntu 22.04 (x86). Kompilatory: LLVM 12.0.1 (Grace), Intel FORTRAN Compiler 19.0 (x86). LS-DYNA R14.1.
Obliczenia energooszczędne dla symulacji Ansys LS-DYNA
Procesor NVIDIA Grace stanowi krok naprzód w efektywności energetycznej dla obciążeń takich jak analiza zderzeń w motoryzacji za pomocą oprogramowania Ansys LS-DYNA. Architektury oparte na Arm, takie jak Grace, oferują korzystną równowagę między wydajnością a efektywnością, co staje się coraz bardziej istotne w HPC, gdzie koszty energii mogą być znaczne. Wyniki benchmarków pokazujące przemianę wydajności/wat przekraczającą 2x w porównaniu do alternatyw x86 podkreślają, jak Arm staje się realną opcją w HPC. W centrum danych z ograniczeniem mocy oznacza to, że można uzyskać nawet dwukrotną wydajność w tym samym budżecie energetycznym, co zwiększa możliwości symulacji. Klienci mogą utrzymać ten sam poziom wydajności, jednocześnie uwalniając dodatkowe zasoby do przyspieszenia. Wraz z nadchodzącym procesorem NVIDIA Vera rola Arm w HPC ma szansę na dalszy rozwój, prawdopodobnie zwiększając zarówno wydajność, jak i efektywność.
Obliczenia nowej generacji dla symulacji Ansys Fluent
Projektowanie efektywnego pojazdu wymaga zrozumienia wydajności aerodynamicznej. Opór powietrza pojazdu bezpośrednio wpływa na zasięg. Dlatego wiele symulacji musi być przeprowadzonych, aby zoptymalizować kształt pojazdu. Te symulacje są kosztowne obliczeniowo, biorąc pod uwagę szeroki zakres czasów i długości skali, które muszą być uchwycone. Szybkie i efektywne uruchamianie narzędzi CFD, takich jak oprogramowanie Ansys Fluent, jest kluczowe.
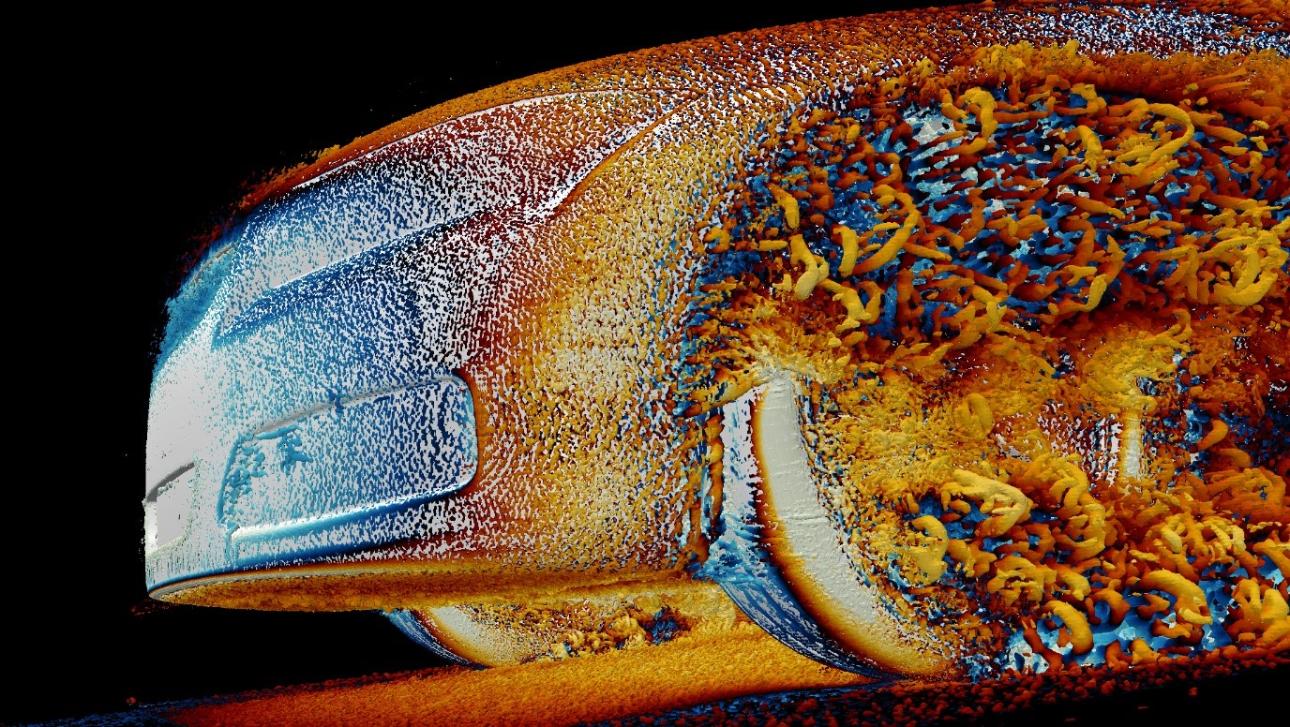
Rysunek 8. Symulacja zestawu danych DrivAer o 2,5 miliarda komórek w oprogramowaniu Ansys Fluent 2024 R2 pokazuje małoskalowe cechy przepływu uchwycone przez symulację tej dokładności.
Ansys uruchomił oprogramowanie Fluent 2024 R2 na superkomputerze Vista Texas Advanced Computing Center (TACC), który składał się z 320 superchipów NVIDIA GH200 Grace Hopper, wszystkie połączone z siecią NVIDIA Quantum-2 400 Gb/s InfiniBand, aby umożliwić skalowalną wydajność. Duża symulacja motoryzacyjna z 2,4 miliarda komórek zajęłaby prawie miesiąc na 2 048 rdzeniach CPU x86, ale na Grace Hopper działała 110 razy szybciej i została ukończona w nieco ponad 6 godzin.
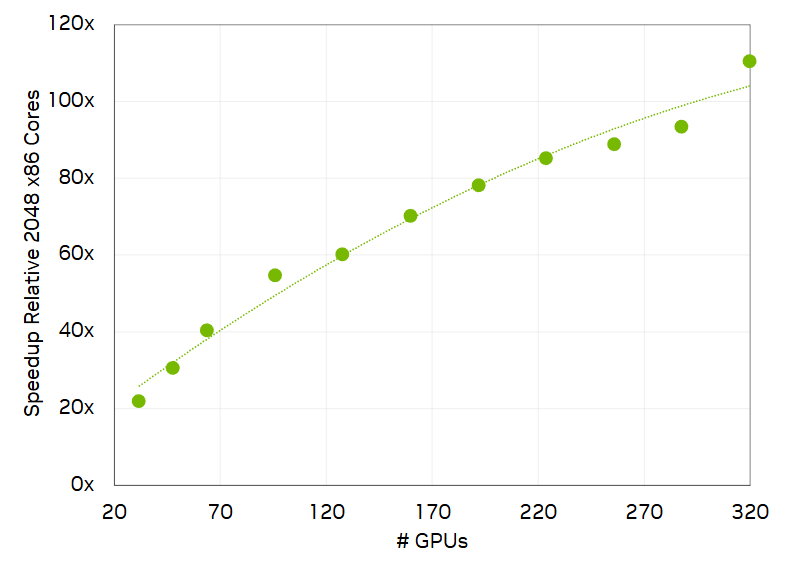
Rysunek 9. Oprogramowanie symulacyjne Ansys Fluent 2024 R2 uruchamiane na TACC na Grace Hopper skalujące się do 320 GPU dla zestawu danych DrivAer o 2,5 miliarda komórek
Oprócz szybkości, efektywność energetyczna i kosztowa są poważnymi kwestiami. Symulacja w oprogramowaniu Ansys Fluent na Grace Hopper również wyróżnia się pod względem tych wskaźników.
Rysunek 10 pokazuje liczbę symulacji DrivAer 2,4B przeprowadzanych przez 1 000 iteracji na kilowatogodzinę w porównaniu do tej samej symulacji na 2 048 rdzeniach CPU x86. Chociaż system Grace Hopper zużywa więcej energii, kończy symulację znacznie szybciej, co pozwala zaoszczędzić ponad sześciokrotnie więcej energii niż CPU. Aby to zobrazować, przeciętne amerykańskie gospodarstwo domowe zużywa 30 kWh dziennie. Dla tej ilości energii, Grace Hopper mógłby przeprowadzić symulację tej wielkości dziewięć razy. System CPU mógłby przeprowadzić ją tylko 1,5 razy.
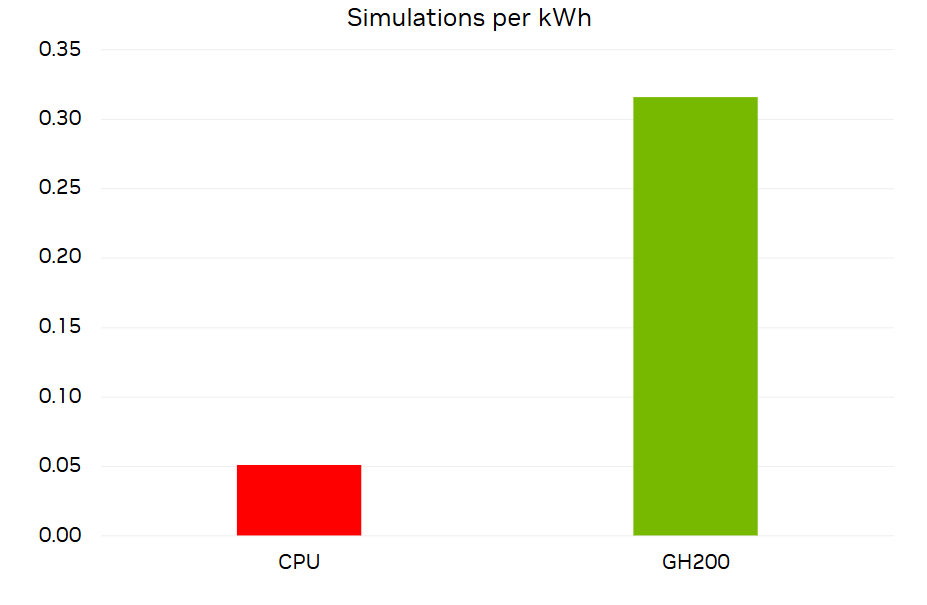
Rysunek 10. Wykres pokazuje liczbę symulacji DrivAer 2,4B, które można przeprowadzić na kilowatogodzinę
Z perspektywy kosztów wydajności przeprowadziliśmy podobną analizę, ale wykorzystaliśmy standardowe ceny dla serwerów CPU i serwerów Grace Hopper. Przy użyteczności superkomputera wynoszącej 3 lata zauważyliśmy 4-krotną przewagę korzystania z Grace Hopper dla dużych symulacji Ansys Fluent, takich jak ta przedstawiona w tym poście.
Obliczyliśmy liczbę symulacji, które można było przeprowadzić na dolara, dzieląc liczbę symulacji DrivAer 2,4B po 1 000 iteracji, które można wykonać w ciągu 3 lat, przez koszt 2 048 rdzeni lub 32 GPU.
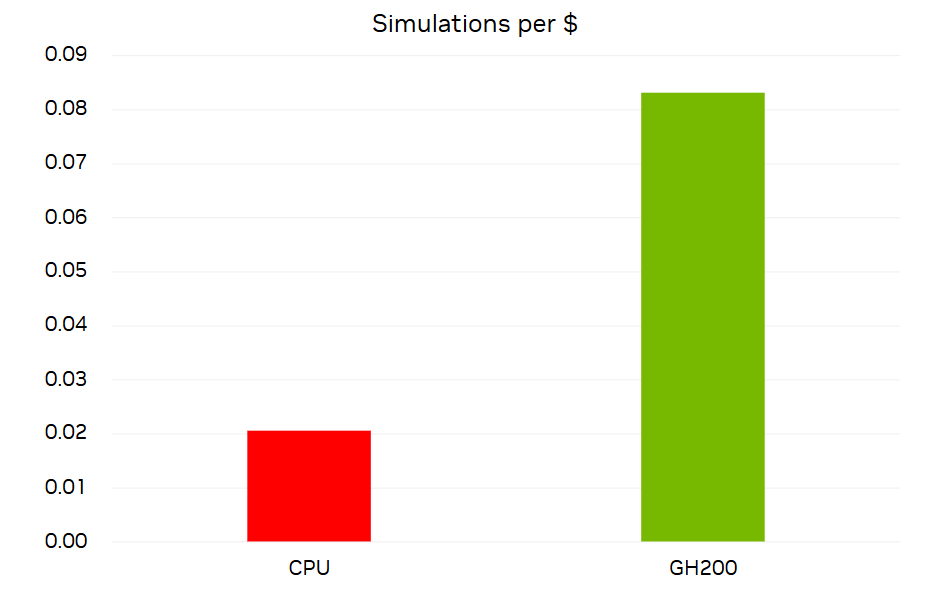
Rysunek 11. Liczba symulacji DrivAer 2,4B, które można przeprowadzić na 1 USD
Podział TACC Vista GH200: 96 GB HBM3 / 120 GB LPDDR, przełącznik NVIDIA Quantum-2 MQM9790 400 Gb/s InfiniBand.
Doświadcz procesora NVIDIA Grace Hopper i procesora NVIDIA Grace
Zarejestruj się, aby przetestować wydajność swojego obciążenia na superchipie NVIDIA Grace lub NVIDIA Grace Hopper. Aplikuj o dostęp do systemu, aby przetestować swoje obciążenie na Thea, połączonym z InfiniBand NVIDIA Quantum-2 środowisku multinode, hostowanym przez HPC-AI Advisory Council.
Powiązane zasoby:
- Sesja GTC: Uzyskaj najwyższą wydajność z Grace Hopper
- Sesja GTC: Cyfrowe bliźniaki napędzane AI: Fizyka w czasie rzeczywistym i przyspieszona symulacja z wykorzystaniem technologii NVIDIA
- Sesja GTC: Optymalizacja wielojęzycznych symulacji naukowych: Studium przypadku superchipa Grace
- SDK: cuDSS
- SDK: AMGX
- SDK: PhysicsNeMo