W miarę jak modele stają się coraz większe i są trenowane na większej ilości danych, stają się bardziej zdolne, co czyni je bardziej użytecznymi. Aby szybko trenować te modele, wymagana jest większa wydajność dostarczana na poziomie centrów danych. Platforma NVIDIA Blackwell, wprowadzona na GTC 2024 i obecnie w pełnej produkcji, integruje siedem typów chipów: GPU, CPU, DPU, chip przełącznika NVLink, przełącznik InfiniBand oraz przełącznik Ethernet. Platforma Blackwell przynosi znaczny skok wydajności na pojedynczy GPU i ma na celu umożliwienie tworzenia jeszcze większych klastrów AI, wspierając rozwój modeli LLM nowej generacji.
W najnowszej edycji MLPerf Training – zestawu benchmarków treningu AI – NVIDIA złożyła swoje pierwsze zgłoszenia korzystając z platformy Blackwell w kategorii podgląd. Wyniki te wykazały znaczne zyski na każdy akcelerator w porównaniu do zgłoszeń opartych na Hopper w każdej próbce benchmarku MLPerf Training. Najważniejsze osiągnięcia obejmują wzrost wydajności na GPU o 2x dla wstępnego treningu GPT-3 oraz 2,2x dla dostrajania niskorankowego (LoRA) modelu Llama 2 70B. NVIDIA zgłosiła również wyniki uruchamiane na Blackwell we wszystkich benchmarkach MLPerf Training w tej rundzie, osiągając solidne zyski w porównaniu do Hopper.
Każdy zgłoszony system zawiera osiem GPU Blackwell działających przy projektowanej mocy cieplnej (TDP) wynoszącej 1,000W, połączonych za pomocą piątej generacji NVLink i najnowszego przełącznika NVLink. Węzły są połączone za pomocą SuperNIC-ów NVIDIA ConnectX-7 oraz przełączników InfiniBand NVIDIA Quantum-2. W przyszłości, GB200 NVL72 – który oferuje więcej mocy obliczeniowej, rozszerzoną domenę NVLink, wyższą przepustowość i pojemność pamięci oraz ścisłą integrację z procesorem NVIDIA Grace – ma zapewnić jeszcze większą wydajność na GPU w porównaniu do HGX B200 oraz umożliwić efektywne skalowanie z SuperNIC-iem ConnectX-8 i nowymi przełącznikami Quantum-X800.
W tym poście przyjrzymy się dokładniej tym doskonałym wynikom.
Udoskonalenie stosu oprogramowania dla Blackwell
Z każdą nową generacją platformy NVIDIA intensywnie współprojektuje sprzęt i oprogramowanie, aby umożliwić deweloperom osiągnięcie wysokiej wydajności obciążenia roboczego. Architektura GPU Blackwell przynosi znaczne skoki w przepustowości obliczeniowej rdzeni Tensor i przepustowości pamięci. Wiele aspektów stosu oprogramowania NVIDIA zostało ulepszonych, aby wykorzystać znacznie poprawione możliwości Blackwell w tej rundzie MLPerf Training, w tym:
- Optymalizowane GEMMs, Convolutions i Multi-head Attention: Nowe rdzenie zostały opracowane, aby efektywnie korzystać z szybszych i bardziej efektywnych rdzeni Tensor w architekturze GPU Blackwell.
- Bardziej efektywne obliczenia i nakładanie komunikacji: Ulepszenia architektury i oprogramowania pozwalają na lepsze wykorzystanie dostępnych zasobów GPU podczas wykonywania w wielu GPU.
- Poprawiona efektywność wykorzystania przepustowości pamięci: Nowe oprogramowanie zostało opracowane jako część biblioteki cuDNN, która wykorzystuje możliwość akceleratora pamięci Tensor (TMA), po raz pierwszy wprowadzonej w architekturze Hopper, poprawiając wykorzystanie przepustowości HBM dla kilku operacji, w tym normalizacji.
- Bardziej wydajne mapowanie równoległe: GPU Blackwell wprowadza większą pojemność HBM, co pozwala na równoległe mapowania modeli językowych, które wykorzystują zasoby sprzętowe w bardziej efektywny sposób.
Dodatkowo, aby poprawić wydajność na Hopper, ulepszyliśmy cuBLAS o wsparcie dla bardziej elastycznych opcji podziału oraz poprawioną lokalność danych. Optymalizowane rdzenie uwagi wielogłowej Blackwell oraz rdzenie konwolucyjne w cuDNN korzystają z silników fuzji czasów wykonania cuDNN. Biblioteka NVIDIA Transformer Engine odegrała kluczową rolę w osiągnięciu zoptymalizowanej wydajności dla modeli językowych dzięki kombinacji opisanych wcześniej optymalizacji.
Kombinacja wielu innowacji w architekturze Blackwell, powyższych optymalizacji oraz wielu innych ulepszeń stosu oprogramowania, które nie zostały tutaj opisane, przyczyniła się do znakomitych wzrostów wydajności we wszystkich obszarach.
Blackwell przynosi ogromny skok w wstępnym treningu LLM
Zestaw MLPerf Training obejmuje benchmark wstępnego treningu LLM oparty na modelu GPT-3 opracowanym przez OpenAI. Test ten ma na celu reprezentację wydajności treningu modeli bazowych na najwyższym poziomie. Na bazie wydajności na GPU, wyniki Blackwell w tej rundzie dostarczyły dwukrotną wydajność w porównaniu do Hopper w jego czwartej zgłoszeniu. Co więcej, w porównaniu do wyników uzyskanych na HGX A100 (niezweryfikowanych przez MLCommons)—opartych na architekturze NVIDIA Ampere—wydajność na GPU wzrosła o około 12x.
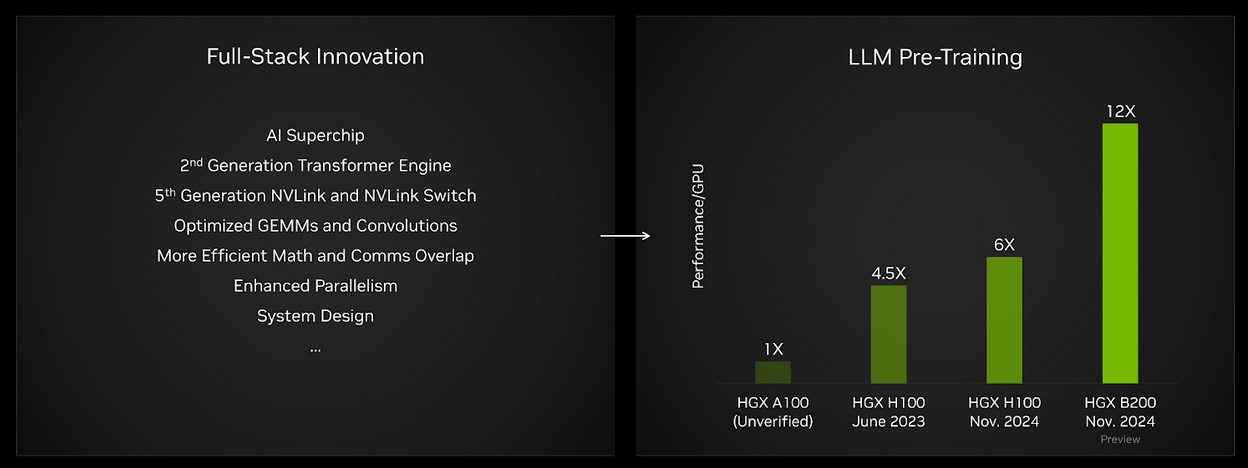
Rysunek 1. Postępy w pełnym stosie NVIDIA przyczyniły się do znacznych skoków wydajności w benchmarku wstępnego treningu LLM MLPerf Training.
MLPerf Training, zamknięte. Wyniki HGX H100 z czerwca 2023, HGX H100 z listopada 2024 oraz HGX B200 zweryfikowane przez Stowarzyszenie MLCommons. Wyniki HGX A100 niezweryfikowane przez MLCommons. Zweryfikowane wyniki uzyskano z wpisów 3.0-2069 (512 GPU H100), 4.1-0060 (512 GPU H100) oraz 4.1-0082 (64 GPU Blackwell) i znormalizowano na GPU. Wydajność/GPU nie jest głównym wskaźnikiem MLPerf Training. Nazwa i logo MLPerf są zarejestrowanymi i niezarejestrowanymi znakami towarowymi stowarzyszenia MLCommons w Stanach Zjednoczonych i innych krajach. Wszelkie prawa zastrzeżone. Niedozwolone użycie surowo zabronione. Szczegóły można znaleźć na stronie: www.mlcommons.org.
Dodatkowo, dzięki większej, o wyższej przepustowości pamięci HBM3e na każdą GPU Blackwell w HGX B200, możliwe było uruchomienie benchmarku GPT-3 za pomocą zaledwie 64 GPU bez kompromisów w wydajności na GPU. Tymczasem, aby osiągnąć optymalną wydajność na GPU przy użyciu HGX H100, wymagana była skala zgłoszenia wynosząca 256 GPU (32 serwery HGX H100). Kombinacja znacznie wyższej przepustowości obliczeniowej na GPU oraz znacznie większej i szybszej pamięci o wysokiej przepustowości pozwala na uruchomienie benchmarku GPT-3 175B na mniejszej liczbie GPU, osiągając jednocześnie doskonałą wydajność na GPU.
Blackwell przyspiesza dostrajanie LLM
Wraz z pojawieniem się dużych i zdolnych modeli LLM społeczności, takich jak rodzina modeli Llama od Meta, przedsiębiorstwa mają dostęp do bogactwa zdolnych modeli wstępnie wytrenowanych. Modele te można dostosować, aby poprawić wydajność w konkretnych zadaniach poprzez dostrajanie. MLPerf Training niedawno dodał benchmark dostrajania LLM, który stosuje niskorankową adaptację (LoRA) – typ efektywnego dostrajania parametrów (PEFT) – do modelu Llama 2 70B.

Rysunek 2. NVIDIA Blackwell podwaja wydajność na GPU w benchmarkach LLM oraz osiąga znaczące zyski wydajności we wszystkich benchmarkach MLPerf Training v4.1 w porównaniu do Hopper.
Porównania wydajności na benchmarku dostrajania Llama 2 70B LoRA opierają się na porównaniu zgłoszeń DGX B200 z 8 GPU wykorzystującymi procesory graficzne Blackwell w zgłoszeniu 4.1-0080 (kategoria podgląd) z zgłoszeniem 8-GPU HGX H100 w zgłoszeniu 4.1-0050 (kategoria dostępna). Porównanie GPT-3 175B porównuje znormalizowaną wydajność na GPU zgłoszenia 256 GPU H100 w wpisie 4.1-0057 (kategoria dostępna) z znormalizowaną wydajnością na GPU zgłoszenia 64 GPU Blackwell w 4.1-0082 (kategoria podgląd). Wyniki zweryfikowane przez Stowarzyszenie MLCommons. Nazwa i logo MLPerf są zarejestrowanymi i niezarejestrowanymi znakami towarowymi stowarzyszenia MLCommons w Stanach Zjednoczonych i innych krajach. Wszelkie prawa zastrzeżone. Niedozwolone użycie surowo zabronione. Szczegóły można znaleźć na stronie www.mlcommons.org.
W benchmarku dostrajania LLM pojedynczy serwer HGX B200 oferuje wydajność większą o 2,2x w porównaniu do serwera HGX H100. Oznacza to, że organizacje mogą szybciej dostosowywać modele LLM przy użyciu Blackwell w porównaniu do Hopper, co przyspiesza czas wdrożenia i, ostatecznie, przynosi większą wartość.
Zgłoszenia Blackwell we wszystkich benchmarkach
NVIDIA zgłosiła wyniki wykorzystujące Blackwell we wszystkich benchmarkach, osiągając znaczące zyski wydajności w każdym z nich.
| Benchmark | Wzrost wydajności Blackwell na GPU w porównaniu do najnowszej wydajności H100 |
| Dostrajanie LLM LoRA | 2.2x |
| Wstępny trening LLM | 2.0x |
| Sieć neuronowa grafowa | 2.0x |
| Przetwarzanie tekstu na obraz | 1.7x |
| Rekomendacje | 1.6x |
| Wykrywanie obiektów | 1.6x |
| Przetwarzanie języka naturalnego | 1.4x |
Tabela 1. Ulepszenia wydajności na Blackwell w porównaniu do Hopper, znormalizowane na GPU.
MLPerf Training v4.1, zamknięte. Wyniki uzyskane 13 listopada 2024 roku z następujących wpisów: 4.1-0048, 4.1-0049, 4.1-0050, 4.1-0051, 4.1-0052, 4.1-0078, 4.1-0079, 4.1-0080, 4.1-0081, 4.1-0082. Przyspieszenia obliczono porównując znormalizowaną wydajność na GPU. Wydajność na GPU nie jest głównym wskaźnikiem MLPerf Training. Nazwa i logo MLPerf są zarejestrowanymi i niezarejestrowanymi znakami towarowymi stowarzyszenia MLCommons w Stanach Zjednoczonych i innych krajach. Wszelkie prawa zastrzeżone. Niedozwolone użycie surowo zabronione. Szczegóły można znaleźć na stronie www.mlcommons.org.
Hopper nadal dostarcza doskonałą wydajność
Architektura NVIDIA Hopper nadal zapewnia najwyższą wydajność wśród dostępnych rozwiązań w MLPerf Training v4.1, zarówno w oparciu o znormalizowaną wydajność na akcelerator, jak i w skali. Na przykład, w benchmarku GPT-3 175B wydajność Hopper na akcelerator wyniosła 1,3x w porównaniu do pierwszego zgłoszenia Hopper w tym benchmarku w MLPerf Training v3.0, dla którego wyniki opublikowano w czerwcu 2023 roku.
Oprócz poprawy wydajności na GPU, NVIDIA znacznie poprawiła efektywność skalowania, umożliwiając zgłoszenie GPT-3 175B przy użyciu 11,616 GPU H100, które nadal trzyma rekordy benchmarkowe zarówno w zakresie wydajności całkowitej, jak i skali zgłoszenia.
NVIDIA również zgłosiła wyniki korzystając z platformy HGX H200. GPU Tensor Core NVIDIA H200 oparty jest na tej samej architekturze Hopper co GPU Tensor Core NVIDIA H100, wyposażony w pamięć HBM3e, co zapewnia 1,8x większą pojemność pamięci i 1,4x większą przepustowość pamięci. W benchmarku niskorankowej adaptacji Llama 2 70B (LoRA) zgłoszenie wykorzystujące 8 GPU H200 osiągnęło o około 16% lepszą wydajność w porównaniu do H100.
Kluczowe wnioski
Platforma NVIDIA Blackwell oznacza znaczący skok wydajności w porównaniu do platformy Hopper, szczególnie w przypadku wstępnego treningu LLM i dostrajania LLM, co zostało udowodnione w wynikach MLPerf Training. Hopper nadal dostarcza świetną wydajność zarówno na GPU, jak i w skali, a optymalizacja oprogramowania dodatkowo zwiększa wydajność od momentu wprowadzenia. W przyszłych rundach MLPerf Training czekamy z niecierpliwością na zgłoszenia Blackwell w jeszcze większej skali, a także na zgłoszenia wyników korzystających z systemu rackowego GB200 NVL72.
Powiązane zasoby
- Sesja GTC: Włączanie wnioskowania Blackwell z użyciem optymalizatora modelu TensorRT
- Sesja GTC: Stabilne i skalowalne szkolenie głębokiego uczenia FP8 na Blackwell
- Sesja GTC: Udoskonal swoje szkolenie LLM: Odporne szkolenie z NeMo
- Kontenery NGC: NVIDIA MLPerf Inference
- Kontenery NGC: NVIDIA MLPerf Inference
- SDK: Codec wideo