Przegląd
Czym jest MLPerf?
Benchmarki MLPerf™ — opracowane przez MLCommons, konsorcjum liderów AI z akademii, laboratoriów badawczych i przemysłu — mają na celu dostarczenie bezstronnych ocen wydajności treningu i wnioskowania dla sprzętu, oprogramowania i usług. Wszystkie testy są przeprowadzane w określonych warunkach. Aby pozostać na czołowej pozycji w branżowych trendach, MLPerf nieustannie ewoluuje, organizując nowe testy w regularnych odstępach czasu i dodając nowe obciążenia, które reprezentują stan wiedzy w AI.
Wnętrze benchmarków MLPerf
MLPerf Inference v5.0 mierzy wydajność wnioskowania na 11 różnych benchmarkach, w tym kilku dużych modelach językowych (LLM), generatywnej AI do przetwarzania tekstu na obraz, rekomendacji, widzeniu komputerowym, segmentacji obrazów biomedycznych oraz sieciach neuronowych grafowych (GNN).
MLPerf Training v4.1 mierzy czas potrzebny do treningu na siedmiu różnych benchmarkach, w tym wstępnym treningu LLM, dostrajaniu LLM, generowaniu obrazów z tekstu, GNN, widzeniu komputerowym, rekomendacjach oraz przetwarzaniu języka naturalnego.
MLPerf HPC v3.0 mierzy wydajność treningu w czterech różnych zastosowaniach obliczeń naukowych, w tym identyfikacji rzek atmosferycznych klimatu, predykcji parametrów kosmologicznych, modelowaniu cząsteczek kwantowych oraz przewidywaniu struktury białek.

Duże modele językowe
Algorytmy głębokiego uczenia trenowane na dużych zbiorach danych, które potrafią rozpoznawać, podsumowywać, tłumaczyć, przewidywać i generować treści dla różnych przypadków użycia.
MLPerf Training wykorzystuje generatywny model językowy GPT-3 z 175 miliardami parametrów i długością sekwencji 2,048 na zbiorze danych C4 dla obciążenia wstępnego treningu LLM. Dla testu dostrajania LLM używany jest model Llama 2 70B w zbiorze danych GovReport z długościami sekwencji 8,192. MLPerf Inference korzysta z modelu Llama 3.1 405B z następującymi zbiorami danych: LongBench, RULER oraz podsumowanie GovReport; model Llama 2 70B z zbiorem danych OpenORCA; model Mixtral 8x7B z zbiorami danych OpenORCA, GSM8K i MBXP; oraz model GPT-J z zbiorem danych CNN-DailyMail.

Przetwarzanie tekstu na obraz
Generuje obrazy na podstawie wskazówek tekstowych.
MLPerf Training wykorzystuje model tekst-na-obraz Stable Diffusion v2, wytrenowany na zbiorze danych LAION-400M-wyfiltered.
MLPerf Inference korzysta z modelu tekst-na-obraz Stable Diffusion XL (SDXL) z podzbiorem 5,000 wskazówek z zbioru danych coco-val-2014.

Rekomendacje
Dostarcza spersonalizowane wyniki w usługach skierowanych do użytkowników, takich jak media społecznościowe czy strony internetowe e-commerce, rozumiejąc interakcje między użytkownikami a przedmiotami usługowymi, takimi jak produkty czy reklamy.
MLPerf Training i Inference wykorzystują model rekomendacji głębokiego uczenia v2 (DLRMv2), który stosuje warstwę krzyżową DCNv2 oraz zbiór danych z wieloma gorącymi wartościami, stworzony na podstawie zbioru danych Criteo.

Wykrywanie obiektów (lekka wersja)
Znajduje przypadki obiektów rzeczywistych, takich jak twarze, rowery i budynki w obrazach lub filmach i określa prostokątny obszar wokół każdego z nich.
MLPerf Training wykorzystuje Single-Shot Detector (SSD) z architekturą ResNeXt50 na podzbiorze zbioru danych Google OpenImages.

Sieci neuronowe grafowe
Wykorzystuje sieci neuronowe zaprojektowane do pracy z danymi ustrukturyzowanymi w postaci grafów.
MLPerf Training i Inference wykorzystują R-GAT z Illinois Graph Benchmark (IGB) - zbiór danych heterogenicznych.

Klasyfikacja obrazów
Przypisuje etykietę z ustalonego zestawu kategorii do obrazu wejściowego, tj. stosuje się do problemów związanych z widzeniem komputerowym.
MLPerf Training i Inference wykorzystują ResNet v1.5 z zbiorem danych ImageNet.

Przetwarzanie języka naturalnego (NLP)
Rozumie tekst, wykorzystując relacje między różnymi słowami w bloku tekstu. Umożliwia zadawanie pytań, parafrazowanie zdań oraz wiele innych zastosowań związanych z językiem.
MLPerf Training wykorzystuje Bidirectional Encoder Representations From Transformers (BERT) na zbiorze danych Wikipedia z dnia 01.01.2020.

Segmentacja obrazów biomedycznych
Wykonuje segmentację wolumetryczną gęstych obrazów 3D do zastosowań medycznych.
MLPerf Training i Inference wykorzystują 3D U-Net z zbiorem danych KiTS19.

Identyfikacja rzek atmosferycznych klimatu
Identifikuje huragany i rzeki atmosferyczne w danych symulacyjnych klimatu.
Wykorzystuje model DeepCAM z zestawem danych symulacji CAM5 + TECA.

Predykcja parametrów kosmologicznych
Rozwiązuje problem regresji obrazów 3D na podstawie danych kosmologicznych.
Wykorzystuje model CosmoFlow z zestawem danych symulacji N-body CosmoFlow.

Modelowanie molekularne kwantowe
Przewiduje energie lub konfiguracje molekularne.
Wykorzystuje model DimeNet++ z zestawem danych Open Catalyst 2020 (OC20).

Przewidywanie struktury białek
Przewiduje trójwymiarową strukturę białka na podstawie jednostkowej łączności aminokwasów.
Wykorzystuje model OpenFold wytrenowany na zbiorze danych OpenProteinSet.
Wyniki benchmarków NVIDIA MLPerf
Platforma NVIDIA HGX™ B200, zasilana przez procesory graficzne NVIDIA Blackwell, piątą generację NVLink™ oraz najnowszy przełącznik NVLink, dostarczyła kolejny ogromny skok w treningu LLM w benchmarku MLPerf Training v4.1. Dzięki nieustannemu inżynierii pełnostackowej na skali centrum danych, NVIDIA nadal przesuwa granice wydajności treningu generatywnej AI, przyspieszając tworzenie i dostosowywanie coraz bardziej zaawansowanych modeli AI.
NVIDIA Blackwell przyspiesza trening LLM

Wyniki MLPerf™ Training v4.1 zostały pobrane z http://www.mlcommons.orgw dniu 13 listopada 2024 roku z następujących wpisów: 4.1-0060 (HGX H100, 2024, 512 GPU) w kategorii dostępnej, 4.1-0082 (HGX B200, 2024, 64 GPU) w kategorii podgląd. Wyniki MLPerf™ Training v3.0, wykorzystujące HGX H100 (2023, 512 GPU), zostały pobrane z wpisu 3.0-2069. Wynik HGX A100, korzystający z 512 GPU, nie został zweryfikowany przez stowarzyszenie MLCommons. Znormalizowana wydajność na GPU nie jest głównym wskaźnikiem MLPerf™ Training. Nazwa i logo MLPerf™ są znakami towarowymi Stowarzyszenia MLCommons w Stanach Zjednoczonych i innych krajach. Wszelkie prawa zastrzeżone. Niedozwolone użycie jest surowo zabronione. Zobacz http://www.mlcommons.org, aby uzyskać więcej informacji.
NVIDIA nadal dostarcza najwyższą wydajność w skali
Platforma NVIDIA, zasilana przez procesory graficzne NVIDIA Hopper™, czwartą generację NVLink z trzeciej generacji NVSwitch™ oraz Quantum-2 InfiniBand, nadal wykazuje niezrównaną wydajność i wszechstronność w MLPerf Training v4.1. NVIDIA dostarczyła najwyższą wydajność w skali we wszystkich siedmiu benchmarkach.
Wydajność maksymalnej skali
| Benchmark | Czas treningu | Liczba GPU |
| LLM (GPT-3 175B) | 3.4 minuty | 11,616 |
| LLM Fine-Tuning (Llama 2 70B-LoRA) | 1.2 minuty | 1,024 |
| Przetwarzanie tekstu na obraz (Stable Diffusion v2) | 1.4 minuty | 1,024 |
| Sieć neuronowa grafowa (R-GAT) | 0.9 minuty | 512 |
| Rekomendacje (DLRM-DCNv2) | 1.0 minuta | 128 |
| Przetwarzanie języka naturalnego (BERT) | 0.1 minuty | 3,472 |
| Wykrywanie obiektów (RetinaNet) | 0.8 minuty | 2,528 |
Wyniki MLPerf™ Training v4.1 zostały pobrane z https://mlcommons.org w dniu 13 listopada 2024 roku z następujących wpisów: 4.1-0012, 4.1-0054, 4.1-0053, 4.1-0059, 4.1-0055, 4.1-0058, 4.1-0056. Nazwa i logo MLPerf™ są znakami towarowymi Stowarzyszenia MLCommons w Stanach Zjednoczonych i innych krajach. Wszelkie prawa zastrzeżone. Niedozwolone użycie jest surowo zabronione. Zobacz https://mlcommons.org, aby uzyskać więcej informacji.
W MLPerf Inference v5.0 NVIDIA osiągnęło doskonałą wydajność we wszystkich benchmarkach. System NVIDIA GB200 NVL72, łączący 36 procesorów NVIDIA Grace™ i 72 procesory graficzne NVIDIA Blackwell w konstrukcji rackowej chłodzonej cieczą, dostarczył do 3,4 razy wyższą przepustowość na GPU w porównaniu do wymagającego benchmarku Llama 3.1 405B w stosunku do poprzedniej generacji architektury NVIDIA Hopper™. Przekłada się to na 30 razy wyższą przepustowość dzięki połączeniu wyższej wydajności na GPU i rozszerzonej domeny NVIDIA NVLink™. W nowo dodanym benchmarku interaktywnym Llama 2 70B, który charakteryzuje się bardziej wymagającymi ograniczeniami latencji czas do pierwszego tokena i token do tokena w porównaniu do standardowego benchmarku Llama 2 70B, osiem procesorów graficznych NVIDIA B200 połączonych przez NVLink potroiło przepustowość w porównaniu do tej samej liczby GPU Hopper. Hopper również osiągnął skumulowaną poprawę do 1,6 razy w kategorii dostępnej w benchmarku Llama 2 70B w ciągu zaledwie roku i dostarczył doskonałe wyniki w kategorii centrum danych, w tym w nowym benchmarku Llama 2 70B Interactive, Llama 3.1 405B oraz GNN.
GB200 NVL72 oferuje najwyższą wydajność wnioskowania w benchmarku Llama 3.1 405B


Wyniki MLPerf™ Training v5.0 zostały pobrane z http://www.mlcommons.org w dniu 2 kwietnia 2025 roku z następujących wpisów: 5.0-0058, 5.0-0060. Wydajność na GPU nie jest głównym wskaźnikiem MLPerf Inference v5.0 i jest obliczana poprzez podzielenie zgłoszonej przepustowości przez liczbę akceleratorów. Nazwa i logo MLPerf™ są znakami towarowymi Stowarzyszenia MLCommons w Stanach Zjednoczonych i innych krajach. Wszelkie prawa zastrzeżone. Niedozwolone użycie jest surowo zabronione. Zobacz http://www.mlcommons.org, aby uzyskać więcej informacji.
B200 Potraja przepustowość wnioskowania LLM w czasie rzeczywistym

MLPerf Inference v5.0, zamknięte, centrum danych. Wyniki pobrano z www.mlcommons.org w dniu 2 kwietnia 2025 roku. Wyniki pochodzą z następujących wpisów: 5.0-0056, 5.0-0060. Nazwa i logo MLPerf™ są znakami towarowymi Stowarzyszenia MLCommons w Stanach Zjednoczonych i innych krajach. Wszelkie prawa zastrzeżone. Niedozwolone użycie jest surowo zabronione. Zobacz http://www.mlcommons.org, aby uzyskać więcej informacji.
NVIDIA H100 Tensor Core przyspieszył platformę NVIDIA dla HPC i AI podczas swojego debiutu w MLPerf HPC v3.0, umożliwiając do 16-krotnego zwiększenia prędkości treningu w ciągu zaledwie trzech lat oraz dostarczając najwyższą wydajność we wszystkich obciążeniach, zarówno w metrykach czasu treningu, jak i przepustowości. Platforma NVIDIA była również jedyną, która zgłosiła wyniki dla każdego obciążenia MLPerf HPC, które obejmują segmentację klimatu, przewidywanie parametrów kosmologicznych, modelowanie cząsteczek kwantowych oraz najnowszy dodatek, przewidywanie struktury białek. Niezrównana wydajność i wszechstronność platformy NVIDIA czynią z niej wybór preferowany do napędzania następnej fali naukowych odkryć wspomaganych przez AI.
Do 16 razy większa wydajność w ciągu trzech lat
Innowacje pełnostackowe NVIDIA przyczyniają się do wzrostu wydajności.

Wyniki MLPerf™ HPC v3.0 zostały pobrane z http://www.mlcommons.org w dniu 8 listopada 2023 roku. Wyniki pochodzą z wpisów 0.7-406, 0.7-407, 1.0-1115, 1.0-1120, 1.0-1122, 2.0-8005, 2.0-8006, 3.0-8006, 3.0-8007, 3.0-8008. Wynik CosmoFlow w wersji 1.0 jest znormalizowany do nowych RCP wprowadzonych w MLPerf HPC v2.0. Wyniki dla wersji 0.7, 1.0 i 2.0 zostały dostosowane w celu usunięcia czasu przechowywania danych z benchmarku, zgodnie z nowymi zasadami przyjętymi dla wersji 3.0, aby umożliwić sprawiedliwe porównania między rundami zgłoszeń. Nazwa i logo MLPerf™ są znakami towarowymi Stowarzyszenia MLCommons w Stanach Zjednoczonych i innych krajach. Wszelkie prawa zastrzeżone. Niedozwolone użycie jest surowo zabronione. Zobacz http://www.mlcommons.org, aby uzyskać więcej informacji.

Wyniki MLPerf™ HPC v3.0 zostały pobrane z http://www.mlcommons.org w dniu 8 listopada 2023 roku. Wyniki pochodzą z wpisów 3.0-8004, 3.0-8009 i 3.0-8010. Nazwa i logo MLPerf™ są znakami towarowymi Stowarzyszenia MLCommons w Stanach Zjednoczonych i innych krajach. Wszelkie prawa zastrzeżone. Niedozwolone użycie jest surowo zabronione. Zobacz http://www.mlcommons.org, aby uzyskać więcej informacji.
Technologia stojąca za wynikami
Złożoność AI wymaga ścisłej integracji wszystkich aspektów platformy. Jak pokazano w benchmarkach MLPerf, platforma AI NVIDIA zapewnia wydajność klasy lidera dzięki najnowocześniejszym procesorom graficznym, potężnym i skalowalnym technologiom interkonektów oraz nowatorskiemu oprogramowaniu — kompleksowe rozwiązanie, które można wdrożyć w centrum danych, w chmurze lub na brzegu sieci z niesamowitymi wynikami.
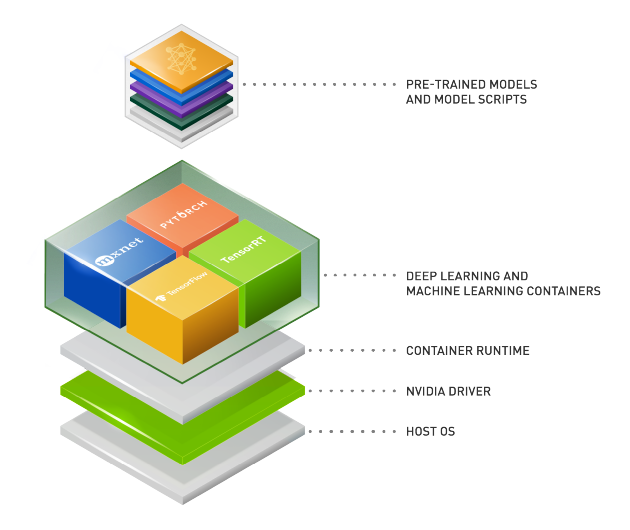
Zoptymalizowane oprogramowanie, które przyspiesza procesy AI
NGC™ katalog jest niezbędnym składnikiem platformy NVIDIA oraz wyników treningu i wnioskowania MLPerf, stanowiąc centrum oprogramowania zoptymalizowanego pod kątem GPU dla AI, HPC i analizy danych, które upraszcza i przyspiesza procesy robocze end-to-end. Z ponad 150 kontenerami klasy przedsiębiorstwa — w tym obciążeniami dla generatywnej AI, AI konwersacyjnej i systemów rekomendacyjnych; setkami modeli AI; oraz specyficznymi dla branży zestawami SDK, które można wdrażać na miejscu, w chmurze lub na brzegu — NGC umożliwia naukowcom danych, badaczom i deweloperom budowanie rozwiązań klasy światowej, gromadzenie wglądów i dostarczanie wartości biznesowej szybciej niż kiedykolwiek.
Infrastruktura AI klasy lidera
Osiągnięcie wyników na światowym poziomie w zakresie treningu i wnioskowania wymaga infrastruktury stworzony specjalnie dla najbardziej złożonych wyzwań AI na świecie. Platforma AI NVIDIA dostarczyła wiodącą wydajność zasilaną przez platformę NVIDIA Blackwell, platformę Hopper, NVLink, NVSwitch™ oraz Quantum InfiniBand. Te technologie są sercem fabryk AI napędzanych przez platformę centrum danych NVIDIA, która stanowi silnik naszych wyników benchmarkowych.
Dodatkowo systemy NVIDIA DGX™ oferują skalowalność, szybkie wdrożenie i niesamowitą moc obliczeniową, co umożliwia każdemu przedsiębiorstwu budowanie infrastruktury AI klasy lidera.


Odblokowywanie generatywnej AI na brzegu z przełomową wydajnością
NVIDIA Jetson Orin oferuje niezrównaną moc obliczeniową AI, dużą zintegrowaną pamięć oraz kompleksowe stosy oprogramowania, zapewniając doskonałą efektywność energetyczną dla najnowszych aplikacji generatywnej AI. Może szybko realizować wnioskowanie dla dowolnych modeli generatywnych AI opartych na architekturze transformatora, oferując wyjątkową wydajność na brzegu w MLPerf.
Gotowy, aby zacząć?
Porozmawiaj z ekspertem produktowym NVIDIA, aby dowiedzieć się więcej o wydajności treningu i wnioskowania w centrum danych.